
"You youngsters do not know your literature!” one of the senior astronomers yelled at some students and us - postdocs - a few years back. One could simply cast this aside as the stereo-typical and age-old battle of the once-young with the currently-young. However, I thought: “He is right - I do not know my literature!”. There were two conclusions that could have been drawn from this: I was simply lazy or it was an impossible task. As a stereotypical human, I strongly favored the latter hypothesis and began researching our scholarly communication.
Most of the focus of my career had been on understanding of the death of stars. However, some part of me has always been a data scientist - finding truths in enormous haystacks and understanding our literature was one of such haystack. Astronomy is very fortunate that essentially all papers from the last 20 years are openly accessible on the ArXiv platform.
I started to look at submission statistics and realized that the growth of papers is exponential. I often present Figure when giving talks that show that the number of papers doubles every 14 years while the human cranial capacity only doubles every 1.5 million years. The discrepancy between those two numbers does represent a problem.

The process of peer review ensures that new results are seen and critically evaluated by other experts in the respective fields. A rapidly growing globalized research means that the numbers of papers and other scientific works, which have to be read and evaluated, rises exponentially. Our work has tried to address this issue by using a novel refereeing process coupled with machine learning.
The astrophysicist Michael Merrifield and the mathematician Donald Saari were one of the first to suggest a new paradigm for awarding telescope time (in a paper titled "Telescope Time Without Tears: A Distributed Approach to Peer Review") by handing the task of the review back to the community scientist who handed in proposal - in effect judging their competition. This system is known as a distributed peer review and scales easily as a growing number of proposers automatically increases the number of reviewers. A few agencies have tried distributed peer review in the last few years, however, unfortunately, these experiments were never widely publicized.
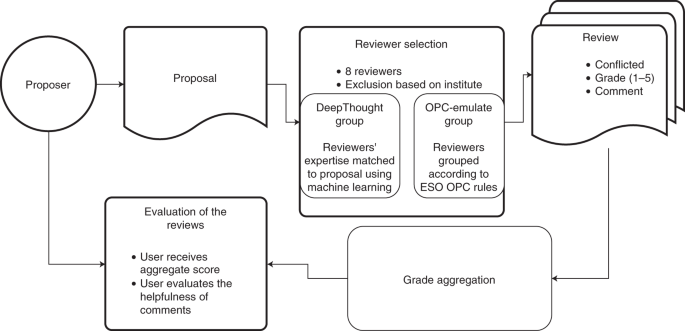
Nando Patat, Head of the Observing Programmes Office, knew about my work on statistics with papers and mentioned that the European Southern Observatory was going to run a distributed peer review experiment. I had already published a paper that showed how machine learning could find papers that are similar using their entire text. This gave me the idea that if I can find similar papers, I might also be able to calculate the similarity of all papers of a given scientist with any given proposal. I was excited to try out an algorithm and potentially ensure that proposals got the best set of reviewers possible.
Within a week, we put together a web-service, tried several algorithms for distributing reviews with reviewers, thought about what questions would help us best judge our experiment and started getting ready for the big day. In October 2017, more and more participants signed up for our experiment. In the end, we had roughly 170 volunteers that would submit their proposals to our experiment (as well as to the normal peer-review process) but more importantly were willing to review the eight papers that each proposer had to look at. The system mostly behaved smoothly and we started to get positive feedback. After several months of number crunching, we had our results: A system that scales in an ever-growing research landscape while seemingly being as fair as the current system.
This work has been one of the most exciting projects in my career. It brings together my love for machine learning with the potential to enact real change in my field. Ultimately, my work with papers and natural language processing aims to make a machine that can retrieve any answer from the vast amount of current and future literature. The presented project is definitely not that - but potentially a step in that direction.


Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in